模型基準測試 SuperCLUE 發(fā)布,訊飛星火認知大模型國內(nèi)第一
來源:搜狐號-IT之家 時間:2023-05-09 15:53:48
 (資料圖片)
(資料圖片)
IT之家 5 月 9 日消息,今日,中文通用大模型綜合性評測基準 SuperCLUE 正式發(fā)布。該基準測試主要關(guān)注以下問題:中文大模型在不同任務(wù)上的表現(xiàn)如何?與國際代表性模型相比,中文大模型的表現(xiàn)達到了何種程度?中文大模型與人類表現(xiàn)相比如何?
該模型可通過多個層面,考研市面上主流的中文 GPT 大模型的能力:
基礎(chǔ)能力: 包括了常見的有代表性的模型能力,如語義理解、對話、邏輯推理、角色模擬、代碼、生成與創(chuàng)作等 10 項能力。 專業(yè)能力: 包括了中學(xué)、大學(xué)與專業(yè)考試,涵蓋了從數(shù)學(xué)、物理、地理到社會科學(xué)等 50 多項能力。 中文特性能力: 針對有中文特點的任務(wù),包括了中文成語、詩歌、文學(xué)、字形等 10 項多種能力。該機構(gòu)利用 SuperCLUE 測試基準,對市面上主流的支持中文的通用大模型進行了評測與排名。從排名中我們可以看出,GPT-4 一騎絕塵,已經(jīng)非常接近人類的能力。國產(chǎn)大模型中訊飛科技研發(fā)的星火認知大模型總排名第三,國內(nèi)排名第一。
以下為該機構(gòu)公布的各個子項目的具體得分。排行榜會定期更新,并于以下網(wǎng)站進行公示。CLUEbenchmarks 官方網(wǎng)站
標簽:
- 模型基準測試 SuperCLUE 發(fā)布,訊飛星火認知大模型國內(nèi)第一
IT之家5月9日消息,今日,中文通用大模型綜合性評測基準SuperCLUE正式發(fā)布。該基準測試主要關(guān)注以下問題:
-
 宏碁暗影騎士?擎游戲本上新:i5-13500H + RTX 4050 版本 6799元
-世界報道 IT之家5月9日消息,宏碁現(xiàn)推出了全新的2023款暗影騎士?擎16游戲本,新機提供了三種配置:i5-13500H、RTX3050版本589
宏碁暗影騎士?擎游戲本上新:i5-13500H + RTX 4050 版本 6799元
-世界報道 IT之家5月9日消息,宏碁現(xiàn)推出了全新的2023款暗影騎士?擎16游戲本,新機提供了三種配置:i5-13500H、RTX3050版本589 -
 全國首條比亞迪旅游云巴線今日在長沙開通,票價 20 元
IT之家5月9日消息,據(jù)比亞迪云巴官方消息,5月9日上午,大王山歡樂云巴通車儀式在湖南湘江新區(qū)大王山云巴站
全國首條比亞迪旅游云巴線今日在長沙開通,票價 20 元
IT之家5月9日消息,據(jù)比亞迪云巴官方消息,5月9日上午,大王山歡樂云巴通車儀式在湖南湘江新區(qū)大王山云巴站 -
 2028奧運會舉辦國家是什么?2028奧運會的舉辦地是哪里? 2028奧運會舉辦國家是什么?2028奧運會舉辦的國家是美國,舉辦地點在洛杉磯,2017年7月,國際奧委會決定
2028奧運會舉辦國家是什么?2028奧運會的舉辦地是哪里? 2028奧運會舉辦國家是什么?2028奧運會舉辦的國家是美國,舉辦地點在洛杉磯,2017年7月,國際奧委會決定 -
 停息掛賬可以一次性結(jié)清嗎?停息掛賬后又逾期會怎樣? 停息掛賬可以一次性結(jié)清嗎可以的,停息掛賬的目的是為了緩解借款人還款壓力。停止計算利息之后,銀行不
停息掛賬可以一次性結(jié)清嗎?停息掛賬后又逾期會怎樣? 停息掛賬可以一次性結(jié)清嗎可以的,停息掛賬的目的是為了緩解借款人還款壓力。停止計算利息之后,銀行不 -
 信用卡逾期信用卡會不會降額度?信用卡逾期不還銀行會怎么辦? 相信目前很多小伙伴對于信用卡都比較感興趣,那么小搜今天在網(wǎng)上也是收集了一些與信用卡相關(guān)的信息來分
信用卡逾期信用卡會不會降額度?信用卡逾期不還銀行會怎么辦? 相信目前很多小伙伴對于信用卡都比較感興趣,那么小搜今天在網(wǎng)上也是收集了一些與信用卡相關(guān)的信息來分
-
 信用卡多長時間算逾期?信用卡是一個月一還嗎 信用卡多長時間算逾期寬限期有三天后算是真正的逾期。一般還款日過后不算逾期,銀行會給到三天的寬限期
信用卡多長時間算逾期?信用卡是一個月一還嗎 信用卡多長時間算逾期寬限期有三天后算是真正的逾期。一般還款日過后不算逾期,銀行會給到三天的寬限期 -
 億佰家5G養(yǎng)生,力創(chuàng)行業(yè)風(fēng)向標 ——正式登陸貴陽市場 近年來,國家對于健康產(chǎn)業(yè)的支持力度越來越大。繼國家提出健康中國戰(zhàn)略以來,國家又陸續(xù)實施了多項有關(guān)大健康產(chǎn)業(yè)的政策,如《健康中國行動
億佰家5G養(yǎng)生,力創(chuàng)行業(yè)風(fēng)向標 ——正式登陸貴陽市場 近年來,國家對于健康產(chǎn)業(yè)的支持力度越來越大。繼國家提出健康中國戰(zhàn)略以來,國家又陸續(xù)實施了多項有關(guān)大健康產(chǎn)業(yè)的政策,如《健康中國行動 -
 信用卡欠7萬有什么后果?信用卡忘記還款了怎么辦? 信用卡欠7萬有什么后果?1、信用卡不還錢會產(chǎn)生逾期違約金和利息;2、信用卡不還錢會在個人征信報告上有記
信用卡欠7萬有什么后果?信用卡忘記還款了怎么辦? 信用卡欠7萬有什么后果?1、信用卡不還錢會產(chǎn)生逾期違約金和利息;2、信用卡不還錢會在個人征信報告上有記 -
 黑龍江停息掛賬常識是什么?主動申請掛賬停息怎么做? 黑龍江停息掛賬常識:什么叫停息掛賬概念?停息掛賬就是借款人因故未能按期歸還貸款,銀行暫停按期計息,所
黑龍江停息掛賬常識是什么?主動申請掛賬停息怎么做? 黑龍江停息掛賬常識:什么叫停息掛賬概念?停息掛賬就是借款人因故未能按期歸還貸款,銀行暫停按期計息,所 -
 上線微軟Microsoft商店 高德地圖PC體驗版來 你知道嗎? 高德地圖PC體驗版上線路線規(guī)劃、信息搜索、收藏和個人主頁高德地圖 PC 體驗版現(xiàn)已上線微軟 Microsoft
上線微軟Microsoft商店 高德地圖PC體驗版來 你知道嗎? 高德地圖PC體驗版上線路線規(guī)劃、信息搜索、收藏和個人主頁高德地圖 PC 體驗版現(xiàn)已上線微軟 Microsoft -
 基金收益是一天還是一周清算? 基金怎么投資能賺到錢? 基金怎么投資能賺到錢?1、分散組合投資分散投資是將資金購買多只不同類型的基金,將資金有效的分散開來
基金收益是一天還是一周清算? 基金怎么投資能賺到錢? 基金怎么投資能賺到錢?1、分散組合投資分散投資是將資金購買多只不同類型的基金,將資金有效的分散開來 -
 股票拉高了為什么還有人買? 100股手續(xù)費是怎么算? 股票拉高了為什么還有人買?1、受迫漲殺跌的投資對策影響,往往會造成散戶在股票大漲的情況下買入2、股票
股票拉高了為什么還有人買? 100股手續(xù)費是怎么算? 股票拉高了為什么還有人買?1、受迫漲殺跌的投資對策影響,往往會造成散戶在股票大漲的情況下買入2、股票 -
 水土流失和土地沙化的區(qū)別有哪些?水土流失與泥石流有什么區(qū)別? 水土流失和土地沙化的區(qū)別有哪些?水土流失是指在水力、風(fēng)力、重力及凍融等自然營力和人類活動作用下,水
水土流失和土地沙化的區(qū)別有哪些?水土流失與泥石流有什么區(qū)別? 水土流失和土地沙化的區(qū)別有哪些?水土流失是指在水力、風(fēng)力、重力及凍融等自然營力和人類活動作用下,水 -
 房屋產(chǎn)權(quán)到期怎么辦?二手房只剩23年產(chǎn)權(quán)可以買嗎? 房屋產(chǎn)權(quán)到期怎么辦?房屋產(chǎn)權(quán)到期指的是土地使用權(quán)到期。如果土地使用權(quán)到期,可以申請辦理續(xù)期。根據(jù)20
房屋產(chǎn)權(quán)到期怎么辦?二手房只剩23年產(chǎn)權(quán)可以買嗎? 房屋產(chǎn)權(quán)到期怎么辦?房屋產(chǎn)權(quán)到期指的是土地使用權(quán)到期。如果土地使用權(quán)到期,可以申請辦理續(xù)期。根據(jù)20 -
 春雨是代表什么時間段的雨?春雨有哪些特點? 春雨是代表什么時間段的雨?春雨指的是春季的雨。春季,四季之一。春,代表著溫暖、生長。春季,陰陽之氣
春雨是代表什么時間段的雨?春雨有哪些特點? 春雨是代表什么時間段的雨?春雨指的是春季的雨。春季,四季之一。春,代表著溫暖、生長。春季,陰陽之氣 -
 陜西個人停息掛賬哪家好?停息掛賬的好處是什么? 陜西個人停息掛賬哪家好?都不容易申請,銀行未必會同意辦理信用卡提掛賬,從銀行方面來看,你停息掛賬不會
陜西個人停息掛賬哪家好?停息掛賬的好處是什么? 陜西個人停息掛賬哪家好?都不容易申請,銀行未必會同意辦理信用卡提掛賬,從銀行方面來看,你停息掛賬不會 -
 離婚了保險受益人是否有效?離婚了保險受益人有效的標準是什么? 一、婚前購買的保險屬于婚前財產(chǎn)嗎婚前購買的保險屬于婚前個人財產(chǎn),不屬于夫妻共同財產(chǎn)。保單是屬于個
離婚了保險受益人是否有效?離婚了保險受益人有效的標準是什么? 一、婚前購買的保險屬于婚前財產(chǎn)嗎婚前購買的保險屬于婚前個人財產(chǎn),不屬于夫妻共同財產(chǎn)。保單是屬于個 -
 回南天有哪些注意事項?回南天吃哪些食物能祛濕? 回南天有哪些注意事項?1、注意安全。天氣的潮濕,行走需要注意人身安全,上下樓梯注意安全,避免打滑摔
回南天有哪些注意事項?回南天吃哪些食物能祛濕? 回南天有哪些注意事項?1、注意安全。天氣的潮濕,行走需要注意人身安全,上下樓梯注意安全,避免打滑摔 -
 中等收入陷阱表示什么含義? 中等收入陷阱的主要特征有什么? 中等收入陷阱表示什么含義?中等收入陷阱是指一個國從低收入階段進入中等收入階段后,經(jīng)濟長期徘徊在中等
中等收入陷阱表示什么含義? 中等收入陷阱的主要特征有什么? 中等收入陷阱表示什么含義?中等收入陷阱是指一個國從低收入階段進入中等收入階段后,經(jīng)濟長期徘徊在中等 -
 保險合同爭議處理有哪些方式?保險合同糾紛的管轄權(quán)如何確定? 一、民法典規(guī)定保險合同能否被撤銷民法典規(guī)定保險合同能被撤銷的。保險合同在具有法定撤銷事由,比如基
保險合同爭議處理有哪些方式?保險合同糾紛的管轄權(quán)如何確定? 一、民法典規(guī)定保險合同能否被撤銷民法典規(guī)定保險合同能被撤銷的。保險合同在具有法定撤銷事由,比如基 -
 交易股票看K線技巧 什么是指標股票? 交易股票看K線技巧1、看K線陰陽和數(shù)量:陰陽意味著多空雙方的對比。陰線越多,說明市場空方力量越強,股
交易股票看K線技巧 什么是指標股票? 交易股票看K線技巧1、看K線陰陽和數(shù)量:陰陽意味著多空雙方的對比。陰線越多,說明市場空方力量越強,股 -
 銀行復(fù)利計算公式是什么?銀行復(fù)利保險是不是好的呢? 銀行復(fù)利計算公式是什么?銀行復(fù)利計算公式可以用來計算存款或投資的復(fù)利,該公式為:FV = PV x (1+r
銀行復(fù)利計算公式是什么?銀行復(fù)利保險是不是好的呢? 銀行復(fù)利計算公式是什么?銀行復(fù)利計算公式可以用來計算存款或投資的復(fù)利,該公式為:FV = PV x (1+r -
 什么是龍卷風(fēng)?龍卷風(fēng)形成的過程是怎樣的? 什么是龍卷風(fēng)?龍卷風(fēng)是一種風(fēng)力極強而范圍不太大的渦旋,狀如漏斗,風(fēng)速極快,破壞力很大。其中心的氣壓
什么是龍卷風(fēng)?龍卷風(fēng)形成的過程是怎樣的? 什么是龍卷風(fēng)?龍卷風(fēng)是一種風(fēng)力極強而范圍不太大的渦旋,狀如漏斗,風(fēng)速極快,破壞力很大。其中心的氣壓 -
 吸脂瘦腿的方法有哪些?大腿吸脂要多少錢? 吸脂瘦腿的方法有哪些?吸脂瘦腿的方法就是通過脂肪抽吸,將大腿脂肪堆積的部位的脂肪給它抽出去,就起到
吸脂瘦腿的方法有哪些?大腿吸脂要多少錢? 吸脂瘦腿的方法有哪些?吸脂瘦腿的方法就是通過脂肪抽吸,將大腿脂肪堆積的部位的脂肪給它抽出去,就起到 -
 保險單要不要本人簽名?保險單合法轉(zhuǎn)讓的前提條件是什么? 一、保險能不能更改被保險人保險不能更改被保險人,在人身保險合同中,投保人、被保險人和受益人分屬于
保險單要不要本人簽名?保險單合法轉(zhuǎn)讓的前提條件是什么? 一、保險能不能更改被保險人保險不能更改被保險人,在人身保險合同中,投保人、被保險人和受益人分屬于 -
 中保研成績最好的SUV車型 理想堡壘安全車身展示 你知道嗎? 中保研成績最好的SUV車型,理想堡壘安全車身亮相日前,理想汽車在安全日活動中展示了理想堡壘安全車身。
中保研成績最好的SUV車型 理想堡壘安全車身展示 你知道嗎? 中保研成績最好的SUV車型,理想堡壘安全車身亮相日前,理想汽車在安全日活動中展示了理想堡壘安全車身。 -
 內(nèi)存不能為written怎么辦?內(nèi)存不能為written的原因是什么? 內(nèi)存不能為written怎么辦?1、通過按快捷鍵WIN+R彈出運行。2、輸入cmd后點擊確定按鈕,進入DOS命令界面。
內(nèi)存不能為written怎么辦?內(nèi)存不能為written的原因是什么? 內(nèi)存不能為written怎么辦?1、通過按快捷鍵WIN+R彈出運行。2、輸入cmd后點擊確定按鈕,進入DOS命令界面。 -
 焦點速遞!仙壇股份:4月實現(xiàn)雞肉產(chǎn)品銷售收入49,630.18萬元 仙壇股份(002746):4月實現(xiàn)雞肉產(chǎn)品銷售收入49,630 18萬元,銷售數(shù)量4 67萬噸,同比變動幅度分別為47 26%、
焦點速遞!仙壇股份:4月實現(xiàn)雞肉產(chǎn)品銷售收入49,630.18萬元 仙壇股份(002746):4月實現(xiàn)雞肉產(chǎn)品銷售收入49,630 18萬元,銷售數(shù)量4 67萬噸,同比變動幅度分別為47 26%、 -
 八方風(fēng)雨是什么意思?八方風(fēng)雨是什么生肖? 八方風(fēng)雨是什么意思?四面八方風(fēng)雨聚會。出 處唐·劉禹錫《郡內(nèi)書情獻裴度侍中留守》:萬乘旌旗分一半,
八方風(fēng)雨是什么意思?八方風(fēng)雨是什么生肖? 八方風(fēng)雨是什么意思?四面八方風(fēng)雨聚會。出 處唐·劉禹錫《郡內(nèi)書情獻裴度侍中留守》:萬乘旌旗分一半, -
 身份證過期影響什么?身份證過期無法轉(zhuǎn)賬嗎? 一、身份證過期影響什么(一)身份證過期,不僅會影響居民在銀行辦理儲蓄等業(yè)務(wù),辦理購房、保險、出國護
身份證過期影響什么?身份證過期無法轉(zhuǎn)賬嗎? 一、身份證過期影響什么(一)身份證過期,不僅會影響居民在銀行辦理儲蓄等業(yè)務(wù),辦理購房、保險、出國護 -
 農(nóng)村醫(yī)保怎樣申請大病救助?大病救助需要什么條件才能申請? 農(nóng)村醫(yī)保怎樣申請大病救助?1、提供申請材料。申請人需要準備身份證、戶口簿、醫(yī)療費用清單、疾病診斷證
農(nóng)村醫(yī)保怎樣申請大病救助?大病救助需要什么條件才能申請? 農(nóng)村醫(yī)保怎樣申請大病救助?1、提供申請材料。申請人需要準備身份證、戶口簿、醫(yī)療費用清單、疾病診斷證 - 宏碁暗影騎士?擎游戲本上新:i5-13500H + RTX 4050 版本 6799元
-世界報道 IT之家5月9日消息,宏碁現(xiàn)推出了全新的2023款暗影騎士?擎16游戲本,新機提供了三種配置:i5-13500H、RTX3050版本589
-
 當前視訊!40萬買寶馬7系同級豪華車!新一代凱迪拉克CT6實車曝光:超帥 40萬買寶馬7系同級豪華車!新一代凱迪拉克CT6實車曝光:超帥
當前視訊!40萬買寶馬7系同級豪華車!新一代凱迪拉克CT6實車曝光:超帥 40萬買寶馬7系同級豪華車!新一代凱迪拉克CT6實車曝光:超帥 -
 票價20元 全國首條旅游云巴線今日開通:比亞迪100%自主知識產(chǎn)權(quán) 觀察 票價20元全國首條旅游云巴線今日開通:比亞迪100%自主知識產(chǎn)權(quán)
票價20元 全國首條旅游云巴線今日開通:比亞迪100%自主知識產(chǎn)權(quán) 觀察 票價20元全國首條旅游云巴線今日開通:比亞迪100%自主知識產(chǎn)權(quán) -
 南轅北轍小古文翻譯和道理是什么? 南轅北轍什么意思? 翻譯為:我今日在上朝的路上遇見一人,他面朝北面駕馬車,告訴我說:我想到楚國去。我說:您到楚國去,
南轅北轍小古文翻譯和道理是什么? 南轅北轍什么意思? 翻譯為:我今日在上朝的路上遇見一人,他面朝北面駕馬車,告訴我說:我想到楚國去。我說:您到楚國去, -
 招商銀行卡輸錯三次密碼多久可以再用?招商銀行卡取款密碼忘了怎么重置? 招商銀行卡輸錯三次密碼多久可以再用招商銀行卡的取款密碼當天連續(xù)輸錯5次會鎖定,次日凌晨00:00-02:00
招商銀行卡輸錯三次密碼多久可以再用?招商銀行卡取款密碼忘了怎么重置? 招商銀行卡輸錯三次密碼多久可以再用招商銀行卡的取款密碼當天連續(xù)輸錯5次會鎖定,次日凌晨00:00-02:00 -
 退休前醫(yī)保交滿還要繼續(xù)交嗎?50歲已交滿30年社保還交嗎? 退休前醫(yī)保交滿還要繼續(xù)交嗎還要繼續(xù)交,因為醫(yī)保費用免繳的前提是退休后,參保人在退休前繳夠規(guī)定年限
退休前醫(yī)保交滿還要繼續(xù)交嗎?50歲已交滿30年社保還交嗎? 退休前醫(yī)保交滿還要繼續(xù)交嗎還要繼續(xù)交,因為醫(yī)保費用免繳的前提是退休后,參保人在退休前繳夠規(guī)定年限 -
 航空器抵押權(quán)適用什么?劫持航空器罪的構(gòu)成要件有哪些? 一、航空器抵押權(quán)適用什么海商法:13、設(shè)定船舶抵押權(quán),由抵押權(quán)人和抵押人共同向船舶登記機關(guān)辦理抵押
航空器抵押權(quán)適用什么?劫持航空器罪的構(gòu)成要件有哪些? 一、航空器抵押權(quán)適用什么海商法:13、設(shè)定船舶抵押權(quán),由抵押權(quán)人和抵押人共同向船舶登記機關(guān)辦理抵押 -
 信用卡逾期停息掛賬可以申請嗎?信用卡逾期三個月會有什么后果 信用卡逾期停息掛賬可以申請嗎當然可以申請了。持卡人逾期沒有能力還款,只要自己的還款意愿很強大那就
信用卡逾期停息掛賬可以申請嗎?信用卡逾期三個月會有什么后果 信用卡逾期停息掛賬可以申請嗎當然可以申請了。持卡人逾期沒有能力還款,只要自己的還款意愿很強大那就 -
 檔案丟了怎么辦?檔案丟了還能進行補救嗎? 一、檔案丟了怎么辦?還能進行補救嗎?檔案丟失可以進行補辦,補辦內(nèi)容:從高中到大學(xué)的各種學(xué)籍材料入學(xué)
檔案丟了怎么辦?檔案丟了還能進行補救嗎? 一、檔案丟了怎么辦?還能進行補救嗎?檔案丟失可以進行補辦,補辦內(nèi)容:從高中到大學(xué)的各種學(xué)籍材料入學(xué) -
 逾期辦理停息掛賬有什么影響?信用卡協(xié)商還款后又逾期怎么辦? 逾期辦理停息掛賬有什么影響?信用卡協(xié)商還款后又逾期怎么辦?下面是小編整理的一些相關(guān)信息,一起來看看
逾期辦理停息掛賬有什么影響?信用卡協(xié)商還款后又逾期怎么辦? 逾期辦理停息掛賬有什么影響?信用卡協(xié)商還款后又逾期怎么辦?下面是小編整理的一些相關(guān)信息,一起來看看 - 停息掛賬可以一次性結(jié)清嗎?停息掛賬后又逾期會怎樣? 停息掛賬可以一次性結(jié)清嗎可以的,停息掛賬的目的是為了緩解借款人還款壓力。停止計算利息之后,銀行不
-
 基金一般持有多長時間? 基金長期持有好還是短期持有好? 基金長期持有好還是短期持有好?長期持有更好,但是長期持有不是百分之百賺錢的。有些投資者認為只要長期
基金一般持有多長時間? 基金長期持有好還是短期持有好? 基金長期持有好還是短期持有好?長期持有更好,但是長期持有不是百分之百賺錢的。有些投資者認為只要長期 -
 城市房地產(chǎn)管理法第三十五條內(nèi)容是什么?二手房買房流程是什么樣的?購買二手房的... 購買二手房的步驟如下:1、根據(jù)需求,與賣方交流,了解實際情況;2、實地看房;3、確定房屋后,起草購房合
城市房地產(chǎn)管理法第三十五條內(nèi)容是什么?二手房買房流程是什么樣的?購買二手房的... 購買二手房的步驟如下:1、根據(jù)需求,與賣方交流,了解實際情況;2、實地看房;3、確定房屋后,起草購房合 -
 銀行基金適合定投嗎?銀行定投基金可以取錢嗎? 銀行基金適合定投嗎?適合。基金定投比較適合波動性大、風(fēng)險高的基金,而銀行當中的股票基金、混合基金、
銀行基金適合定投嗎?銀行定投基金可以取錢嗎? 銀行基金適合定投嗎?適合。基金定投比較適合波動性大、風(fēng)險高的基金,而銀行當中的股票基金、混合基金、 -
 場內(nèi)基金交易要印花稅嗎?場內(nèi)基金可以隨時買賣嗎? 場內(nèi)基金交易要印花稅嗎?基金交易是不收印花稅的,無論是場內(nèi)基金還是場外基金,都不需要收取印花稅。交
場內(nèi)基金交易要印花稅嗎?場內(nèi)基金可以隨時買賣嗎? 場內(nèi)基金交易要印花稅嗎?基金交易是不收印花稅的,無論是場內(nèi)基金還是場外基金,都不需要收取印花稅。交 -
 基金補倉盈利技巧是什么?怎么波段操作指數(shù)基金法? 基金補倉盈利技巧是什么?怎么波段操作指數(shù)基金法?以下是小編為您整理的內(nèi)容,希望對您有所幫助。基金補
基金補倉盈利技巧是什么?怎么波段操作指數(shù)基金法? 基金補倉盈利技巧是什么?怎么波段操作指數(shù)基金法?以下是小編為您整理的內(nèi)容,希望對您有所幫助。基金補 -
 五一期間什么理財產(chǎn)品好? 理財產(chǎn)品到期后什么時候到賬? 五一期間什么理財產(chǎn)品好?【1】國債逆回購國債逆回購作為一種固定期限的短期理財產(chǎn)品,期限最短1天,最長
五一期間什么理財產(chǎn)品好? 理財產(chǎn)品到期后什么時候到賬? 五一期間什么理財產(chǎn)品好?【1】國債逆回購國債逆回購作為一種固定期限的短期理財產(chǎn)品,期限最短1天,最長 -
 民法典第一百八十八條的內(nèi)容有什么呢?欠條的訴訟時效是多少年? 欠條的訴訟時效是三年。根據(jù)2021年生效的《民法典》第一百八十八條的規(guī)定,向人民法院請求保護民事權(quán)利
民法典第一百八十八條的內(nèi)容有什么呢?欠條的訴訟時效是多少年? 欠條的訴訟時效是三年。根據(jù)2021年生效的《民法典》第一百八十八條的規(guī)定,向人民法院請求保護民事權(quán)利 -
 離心風(fēng)機的作用和用途是什么?離心風(fēng)機的工作原理是什么? 離心風(fēng)機的作用和用途是什么?1、離心風(fēng)機離心風(fēng)機屬于葉輪機械的一種,是一種比較精密的運轉(zhuǎn)機械,依靠
離心風(fēng)機的作用和用途是什么?離心風(fēng)機的工作原理是什么? 離心風(fēng)機的作用和用途是什么?1、離心風(fēng)機離心風(fēng)機屬于葉輪機械的一種,是一種比較精密的運轉(zhuǎn)機械,依靠 -
 win11怎么免密碼自動登錄 新電腦只有一個c盤怎么辦? win11怎么免密碼自動登錄 新電腦只有一個c盤怎么辦?第一種方法:通過策略組設(shè)置方法第一步:按下鍵盤上
win11怎么免密碼自動登錄 新電腦只有一個c盤怎么辦? win11怎么免密碼自動登錄 新電腦只有一個c盤怎么辦?第一種方法:通過策略組設(shè)置方法第一步:按下鍵盤上 -
 航班延誤補償標準是什么?飛機延誤4小時含以上不超過8小時給賠償嗎? 一、飛機延誤什么時候給賠償飛機延誤4小時含以上不超過8小時給賠償。只要是航空公司自身原因,包括機械
航班延誤補償標準是什么?飛機延誤4小時含以上不超過8小時給賠償嗎? 一、飛機延誤什么時候給賠償飛機延誤4小時含以上不超過8小時給賠償。只要是航空公司自身原因,包括機械 -
 新股當日可以賣嗎? 新股中簽一般能賺多少? 新股當日可以賣嗎?新股當日可以賣,但投資者也可以選擇不售出。新股中簽以后,投資者確保可以有充裕的資
新股當日可以賣嗎? 新股中簽一般能賺多少? 新股當日可以賣嗎?新股當日可以賣,但投資者也可以選擇不售出。新股中簽以后,投資者確保可以有充裕的資 -
 不當?shù)美脑V訟時效一般是多長時間?民法典第一百八十八條的內(nèi)容是什么? 不當?shù)美脑V訟時效為權(quán)利人知道或應(yīng)當知道權(quán)利受侵害之日起三年。根據(jù)2021年實施的《民法典》第一百八
不當?shù)美脑V訟時效一般是多長時間?民法典第一百八十八條的內(nèi)容是什么? 不當?shù)美脑V訟時效為權(quán)利人知道或應(yīng)當知道權(quán)利受侵害之日起三年。根據(jù)2021年實施的《民法典》第一百八 -
 反擔(dān)保方式是什么意思?反擔(dān)保為什么不直接擔(dān)保? 反擔(dān)保方式是什么意思?反擔(dān)保是指擔(dān)保人要求債務(wù)人為其提供的擔(dān)保,第三人為債務(wù)人向債權(quán)人提供擔(dān)保的,
反擔(dān)保方式是什么意思?反擔(dān)保為什么不直接擔(dān)保? 反擔(dān)保方式是什么意思?反擔(dān)保是指擔(dān)保人要求債務(wù)人為其提供的擔(dān)保,第三人為債務(wù)人向債權(quán)人提供擔(dān)保的,
熱門資訊
-
 網(wǎng)頁顯示404notfound怎么辦?404notfound是什么意思? 網(wǎng)頁顯示404notfound怎么辦?網(wǎng)頁出...
網(wǎng)頁顯示404notfound怎么辦?404notfound是什么意思? 網(wǎng)頁顯示404notfound怎么辦?網(wǎng)頁出... - 億佰家5G養(yǎng)生,力創(chuàng)行業(yè)風(fēng)向標 ——正式登陸貴陽市場 近年來,國家對于健康產(chǎn)業(yè)的支持力...
-
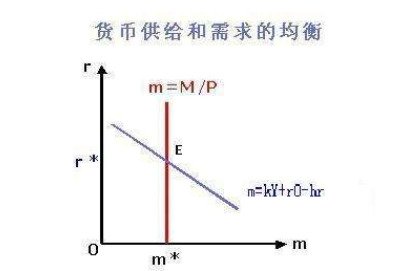 供給函數(shù)名詞解釋,供給函數(shù)曲線繪制 一、供給函數(shù)名詞解釋所謂供給,是...
供給函數(shù)名詞解釋,供給函數(shù)曲線繪制 一、供給函數(shù)名詞解釋所謂供給,是... -
 合同債權(quán)轉(zhuǎn)讓的概念是什么?合同債權(quán)的轉(zhuǎn)讓有哪些條件? 合同債權(quán)轉(zhuǎn)讓的概念是什么?合同債...
合同債權(quán)轉(zhuǎn)讓的概念是什么?合同債權(quán)的轉(zhuǎn)讓有哪些條件? 合同債權(quán)轉(zhuǎn)讓的概念是什么?合同債...
觀察
圖片新聞
- 黑龍江停息掛賬常識是什么?主動申請掛賬停息怎么做? 黑龍江停息掛賬常識:什么叫停息掛...
-
 信用卡逾期怎么辦?欠信用卡還不上銀行起訴就一定會坐牢嗎? 相信目前很多小伙伴對于信用卡都比...
信用卡逾期怎么辦?欠信用卡還不上銀行起訴就一定會坐牢嗎? 相信目前很多小伙伴對于信用卡都比... -
 無力償還信用卡可以要求配偶還債嗎?信用卡逾期半年怎么辦? 相信目前很多小伙伴對于信用卡都比...
無力償還信用卡可以要求配偶還債嗎?信用卡逾期半年怎么辦? 相信目前很多小伙伴對于信用卡都比... -
 蠟燭圖該怎么看?蠟燭圖技術(shù)分析講解 蠟燭圖該怎么看?蠟燭圖本身上可以...
蠟燭圖該怎么看?蠟燭圖技術(shù)分析講解 蠟燭圖該怎么看?蠟燭圖本身上可以...
精彩新聞
- 網(wǎng)頁顯示404notfound怎么辦?404notfound是什么意思? 網(wǎng)頁顯示404notfound怎么辦?網(wǎng)頁出...
-
 銀行停息掛賬的申請條件有哪些?什么是停息掛賬? 銀行停息掛賬的申請條件有哪些?停...
銀行停息掛賬的申請條件有哪些?什么是停息掛賬? 銀行停息掛賬的申請條件有哪些?停... - 婚前購買的保險在離婚時怎么處理?保單是屬于個人財產(chǎn)嗎? 一、婚前購買的保險屬于婚前財產(chǎn)嗎...
-
 中華人民共和國民法典第五百一十條內(nèi)容是什么?二手房注意事項都有哪些? 二手房中要注意以下注意事項:注意...
中華人民共和國民法典第五百一十條內(nèi)容是什么?二手房注意事項都有哪些? 二手房中要注意以下注意事項:注意... -
 處于高估的基金可以定投嗎?基金定投幾天可以取出來? 處于高估的基金可以定投嗎?基金定...
處于高估的基金可以定投嗎?基金定投幾天可以取出來? 處于高估的基金可以定投嗎?基金定... -
 外墻保溫材料有哪些種類?外墻保溫材料有何作用? 外墻保溫材料有哪些種類?1、無機活...
外墻保溫材料有哪些種類?外墻保溫材料有何作用? 外墻保溫材料有哪些種類?1、無機活... -
 C盤變紅了如何清理?C盤變紅了怎么辦? C盤變紅了如何清理?方法一:緩存清...
C盤變紅了如何清理?C盤變紅了怎么辦? C盤變紅了如何清理?方法一:緩存清... -
 支付寶購買的公募REITs如何賣出?公募REITs能不能買? 支付寶購買的公募REITs如何賣出公...
支付寶購買的公募REITs如何賣出?公募REITs能不能買? 支付寶購買的公募REITs如何賣出公... -
 逾期打12378能解決分期還款嗎?信用卡5萬逾期必須坐牢嗎? 逾期打12378能解決分期還款嗎?信用...
逾期打12378能解決分期還款嗎?信用卡5萬逾期必須坐牢嗎? 逾期打12378能解決分期還款嗎?信用... -
 360軟件管家下載路徑怎么改?360軟件小助手是什么? 很多人都喜歡用軟件管家來對電腦中...
360軟件管家下載路徑怎么改?360軟件小助手是什么? 很多人都喜歡用軟件管家來對電腦中... - 模型基準測試 SuperCLUE 發(fā)布,訊飛星火認知大模型國內(nèi)第一
IT之家5月9日消息,今日,中文通用...
-
 二手房過戶費用都有哪些內(nèi)容?中華人民共和國契稅暫行條例第三條契稅稅率為多少? 二手房過戶需要的費用有:購房款;...
二手房過戶費用都有哪些內(nèi)容?中華人民共和國契稅暫行條例第三條契稅稅率為多少? 二手房過戶需要的費用有:購房款;... -
 被打后還手是互毆?高鐵被掌摑女子拒絕和解 羅翔科普:正當防衛(wèi) 全球速遞 被打后還手是互毆?高鐵被掌摑女子...
被打后還手是互毆?高鐵被掌摑女子拒絕和解 羅翔科普:正當防衛(wèi) 全球速遞 被打后還手是互毆?高鐵被掌摑女子... -
 世紀天鴻股價暴漲 凈利10年止步不前凈利率8%徘徊 牽涉人工智能,世紀天鴻(300654 S...
世紀天鴻股價暴漲 凈利10年止步不前凈利率8%徘徊 牽涉人工智能,世紀天鴻(300654 S... -
 儲蓄國債托管賬戶是不是只能在證券交易日才能開戶? 怎么開通國債托管賬戶? 儲蓄國債托管賬戶是不是只能在證券...
儲蓄國債托管賬戶是不是只能在證券交易日才能開戶? 怎么開通國債托管賬戶? 儲蓄國債托管賬戶是不是只能在證券... -
 建行大額存單2023年最新利率是多少?建設(shè)銀行3年期大額存單利率是多少? 建行大額存單2023年最新利率是多少...
建行大額存單2023年最新利率是多少?建設(shè)銀行3年期大額存單利率是多少? 建行大額存單2023年最新利率是多少... -
 授權(quán)委托書的委托期限怎么寫?授權(quán)委托書的法律效力怎么樣? 一、授權(quán)委托書需要受托人簽字嗎需...
授權(quán)委托書的委托期限怎么寫?授權(quán)委托書的法律效力怎么樣? 一、授權(quán)委托書需要受托人簽字嗎需... -
 民事訴訟律師費應(yīng)該誰承擔(dān)?打官司如何請律師? 一、民事訴訟律師費應(yīng)該誰承擔(dān)1、...
民事訴訟律師費應(yīng)該誰承擔(dān)?打官司如何請律師? 一、民事訴訟律師費應(yīng)該誰承擔(dān)1、... -
 基金的操作技巧有哪些?如何調(diào)整基金投資策略? 基金的操作技巧有哪些?如何調(diào)整基...
基金的操作技巧有哪些?如何調(diào)整基金投資策略? 基金的操作技巧有哪些?如何調(diào)整基... - 2028奧運會舉辦國家是什么?2028奧運會的舉辦地是哪里? 2028奧運會舉辦國家是什么?2028奧...
- 全國首條比亞迪旅游云巴線今日在長沙開通,票價 20 元
IT之家5月9日消息,據(jù)比亞迪云巴官...
-
 齊衡結(jié)局?文炎敬最后做了宰相嗎? 齊衡沒有跟盛明蘭在一起,而是跟妻...
齊衡結(jié)局?文炎敬最后做了宰相嗎? 齊衡沒有跟盛明蘭在一起,而是跟妻... -
 win11能上qq但是打不開網(wǎng)頁怎么辦?qq能登陸網(wǎng)頁打不開是什么情況? win11能上qq但是打不開網(wǎng)頁怎么辦?...
win11能上qq但是打不開網(wǎng)頁怎么辦?qq能登陸網(wǎng)頁打不開是什么情況? win11能上qq但是打不開網(wǎng)頁怎么辦?... -
 信用卡協(xié)商停息掛賬怎么處理?信用卡停息掛賬利弊是什么? 信用卡協(xié)商停息掛賬怎么處理?1、給...
信用卡協(xié)商停息掛賬怎么處理?信用卡停息掛賬利弊是什么? 信用卡協(xié)商停息掛賬怎么處理?1、給... -
 800毫升洗發(fā)水能托運嗎?托運液體可以帶多少毫升? 800毫升洗發(fā)水能托運嗎根據(jù)相關(guān)規(guī)...
800毫升洗發(fā)水能托運嗎?托運液體可以帶多少毫升? 800毫升洗發(fā)水能托運嗎根據(jù)相關(guān)規(guī)... -
 從眾消費是什么意思?為什么會有從眾消費心理現(xiàn)象? 從眾消費是什么意思?從眾消費是指...
從眾消費是什么意思?為什么會有從眾消費心理現(xiàn)象? 從眾消費是什么意思?從眾消費是指... -
 白羊女待人熱情大方坦誠不做作 只是不習(xí)慣主動錯過就不再聯(lián)系? 白羊女:不習(xí)慣主動白羊女不習(xí)慣主...
白羊女待人熱情大方坦誠不做作 只是不習(xí)慣主動錯過就不再聯(lián)系? 白羊女:不習(xí)慣主動白羊女不習(xí)慣主... -
 身份證到期怎么辦?身份證過期后是不可以用來乘坐飛機的嗎? 一、身份證使用期限到了能坐飛機嗎...
身份證到期怎么辦?身份證過期后是不可以用來乘坐飛機的嗎? 一、身份證使用期限到了能坐飛機嗎... -
 彩禮屬于夫妻共同財產(chǎn)嗎?彩禮錢是用來干嘛的? 彩禮一般不屬于夫妻共同財產(chǎn)。在婚...
彩禮屬于夫妻共同財產(chǎn)嗎?彩禮錢是用來干嘛的? 彩禮一般不屬于夫妻共同財產(chǎn)。在婚... -
 貸款一年可以提前還款幾次?提前還款需要違約金嗎? 貸款一年可以提前還款幾次?房貸提...
貸款一年可以提前還款幾次?提前還款需要違約金嗎? 貸款一年可以提前還款幾次?房貸提... -
 摘帽會漲停嗎? 什么情況下摘星不摘帽? 摘帽會漲停嗎?摘帽是否會漲停需要...
摘帽會漲停嗎? 什么情況下摘星不摘帽? 摘帽會漲停嗎?摘帽是否會漲停需要... -
 身份證補辦異地辦理要多久?異地補辦身份證去哪里辦? 一、身份證補辦異地辦理要多久異地...
身份證補辦異地辦理要多久?異地補辦身份證去哪里辦? 一、身份證補辦異地辦理要多久異地... - 欠條的訴訟時效是多少年?民法典第一百八十八條的內(nèi)容有什么呢? 欠條的訴訟時效是三年。根據(jù)2021年...
-
 你知道曲終人散意思是什么嗎?曲終人散出自哪里呢? 曲終人散的意思是:樂曲演奏完畢,...
你知道曲終人散意思是什么嗎?曲終人散出自哪里呢? 曲終人散的意思是:樂曲演奏完畢,... -
 上海留學(xué)生落戶容易嗎?留學(xué)生在上海落戶口需要哪些條件? 上海留學(xué)生落戶容易嗎?出國留學(xué)半...
上海留學(xué)生落戶容易嗎?留學(xué)生在上海落戶口需要哪些條件? 上海留學(xué)生落戶容易嗎?出國留學(xué)半... -
 萬惡的資本主義的由來,資本主義是什么意思? 萬惡的資本主義的由來,資本主義是...
萬惡的資本主義的由來,資本主義是什么意思? 萬惡的資本主義的由來,資本主義是... -
 武漢醫(yī)保卡可以在外地用嗎?武漢醫(yī)保在湖北省內(nèi)通用嗎? 武漢醫(yī)保卡可以在外地用嗎可以。武...
武漢醫(yī)保卡可以在外地用嗎?武漢醫(yī)保在湖北省內(nèi)通用嗎? 武漢醫(yī)保卡可以在外地用嗎可以。武... -
 牛二層皮是真的皮嗎?牛二層皮的基本介紹 牛二層皮是在牛皮的第一層廢料破碎...
牛二層皮是真的皮嗎?牛二層皮的基本介紹 牛二層皮是在牛皮的第一層廢料破碎... -
 WPS內(nèi)容為什么沒編輯完就顯示下一頁?WPS內(nèi)容沒編輯完就顯示下一頁的解決教程 WPS內(nèi)容為什么沒編輯完就顯示下一...
WPS內(nèi)容為什么沒編輯完就顯示下一頁?WPS內(nèi)容沒編輯完就顯示下一頁的解決教程 WPS內(nèi)容為什么沒編輯完就顯示下一... -
 熬夜吃什么比較好?熬夜是指幾點到幾點? 熬夜吃什么比較好保持足夠的飲水量...
熬夜吃什么比較好?熬夜是指幾點到幾點? 熬夜吃什么比較好保持足夠的飲水量... -
 如何選出熱點龍頭股? 股東人數(shù)減少有什么影響? 如何選出熱點龍頭股?了解熱點概念...
如何選出熱點龍頭股? 股東人數(shù)減少有什么影響? 如何選出熱點龍頭股?了解熱點概念... -
 手臂吸脂減肥方法有哪些?減肥訓(xùn)練營多少錢一個月? 手臂吸脂減肥方法有哪些?一、脂肪...
手臂吸脂減肥方法有哪些?減肥訓(xùn)練營多少錢一個月? 手臂吸脂減肥方法有哪些?一、脂肪... -
 retis收益率高嗎?什么是公募REITs? retis收益率高嗎?從首批REITs的募...
retis收益率高嗎?什么是公募REITs? retis收益率高嗎?從首批REITs的募... -
 股指期貨套利會虧錢嗎?跨期套利能穩(wěn)定收益嗎? 股指期貨套利會虧錢嗎?可能會虧錢...
股指期貨套利會虧錢嗎?跨期套利能穩(wěn)定收益嗎? 股指期貨套利會虧錢嗎?可能會虧錢... -
 巴菲特對蘋果持倉沒有占到投資組合的35% 你知道嗎? 巴菲特股東大會正式舉行,巴菲特:...
巴菲特對蘋果持倉沒有占到投資組合的35% 你知道嗎? 巴菲特股東大會正式舉行,巴菲特:... -
 臺風(fēng)天氣如何自救?遇到極端暴雨天氣該如何做? 臺風(fēng)天氣如何自救?要隨時留意氣象...
臺風(fēng)天氣如何自救?遇到極端暴雨天氣該如何做? 臺風(fēng)天氣如何自救?要隨時留意氣象... -
 信用卡逾期是什么意思?逾期多久會被列入失信人名單 信用卡逾期是什么意思很多人以為信...
信用卡逾期是什么意思?逾期多久會被列入失信人名單 信用卡逾期是什么意思很多人以為信... -
 雙子是當之無愧的情癡 認定一個人后根本就不會再看別的女人一眼? 天蝎座:無法忘懷你的美好雖然平日...
雙子是當之無愧的情癡 認定一個人后根本就不會再看別的女人一眼? 天蝎座:無法忘懷你的美好雖然平日... -
 天津居住證辦理流程是怎樣?居住證辦理的流程有哪些? 一、長沙市辦理居住證辦理流程居住...
天津居住證辦理流程是怎樣?居住證辦理的流程有哪些? 一、長沙市辦理居住證辦理流程居住... -
 金牛座一開始就是奔著結(jié)婚去的 若是逼不得已分手還天天想著復(fù)合? 金牛座:用情太深能讓內(nèi)斂的金牛座...
金牛座一開始就是奔著結(jié)婚去的 若是逼不得已分手還天天想著復(fù)合? 金牛座:用情太深能讓內(nèi)斂的金牛座...